InvestigatorAI is a investigation assistant built to explore questions that don’t have simple answers. Think of something like:
“Who really controls Costruzioni Ferretti Srl, and are there conflicts of interest with ex-mayor Luigi Conti in the awarding of public contracts by Comune di Brescia in the period 2022–2023?”
Questions like this don’t resolve with a single search or a single model response. They require moving through layers of information: understanding corporate ownership structures, following how individuals appear across different roles and time periods, and connecting that to public procurement data. On top of that, the system has to read unstructured documents, pull out supporting evidence, and continuously weigh how reliable each signal actually is.
This is the kind of workflow that naturally pushes toward a multi-agent design. Different components handle different parts of the problem, from structured graph queries to vector-based retrieval, all the way to observability tools that make it possible to inspect and understand what the system is doing step by step.
System architecture
Bolt :7687 · Browser :7474
Spring Data Neo4j · @Query projections
REST :6333 · gRPC :6334
MLX embed server · Nomic ModernBERT
The six layers are organized along a single principle: everything below the agent layer is replaceable without ever touching the reasoning logic above it. The agents don’t interact with Neo4j or Qdrant directly; instead, they operate through a set of named tools that define the only contract between reasoning and storage.
That separation is what makes the system flexible. You can swap Qdrant for Weaviate, introduce a Redis caching layer, or change the embedding model entirely, and none of it propagates upward into prompts or routing logic.
Why multi-agent
At the core of this system, an agent is nothing more than a Large Language Model running under a fixed system prompt and a tightly controlled set of tools exposed through a Java callable interface. It does not operate in an open world. It operates inside a boundary that is explicitly defined: what it can see, what it can call, and what it can never access.
Even the supervisor does not break this pattern. It is itself an agent, with a single distinction: its tools are the specialist agents. In other words, orchestration is just another layer of constrained reasoning, not a separate class of intelligence.
This structure matters because the problem space is inherently heterogeneous. A single corporate ownership query can unfold into many different kinds of work: decomposing ambiguous questions into sub-problems, routing each fragment to the correct data source, traversing graph relationships, ranking evidence from unstructured documents, and finally synthesizing a structured answer with explicit confidence signals. Each of these steps behaves differently, depends on different context, and fails in its own distinct way.
Multi-agent design is simply a way of acknowledging that reality. By isolating responsibilities into separate agents, each with its own prompt and tool boundary, the system turns complexity into compartments. Failures stop propagating silently across the stack. And perhaps more importantly, no agent can ever drift outside its scope or fabricate evidence that is not grounded in the tools it was explicitly given.
From query to agents
The reference investigation query was the thing that shaped the design in the first place. Each part of it leans on a different kind of data access: ownership structure through graph traversal, conflicts of interest through multi-hop relationships across roles and contracts, individual profiles across both structured graph data and unstructured document mentions. That natural fragmentation is what defined the system’s boundaries, how agents were separated and what tools each of them was allowed to use.
The query maps to three specialist agents and two cross-cutting ones. CorporateAgent and FinancialFlowAgent both read from Neo4j but sit on different slices of the graph: ownership structure on one side, contract awards and amounts on the other. PersonProfileAgent is the one that spans both stores, joining a person’s graph relationships with their mentions across documents. DocumentAgent and SourceVerificationAgent aren’t tied to any single fragment of the query. They run across the whole set of intermediate findings, pulling corroborating evidence from the document store and cross-checking claims before a confidence level gets assigned.
The supervisor receives the raw query along with any focusEntities provided in the API request. There is no preprocessing step for entity resolution or date extraction before the model. The supervisor LLM interprets the query, selects which specialist agents to invoke, and passes structured arguments such as company names, person names, and date ranges to their tools. Entity matching itself happens inside Cypher queries through exact name matching.
At runtime, the SupervisorAgent orchestrates these specialists as tools and adapts the execution flow based on intermediate results. If CorporateAgent reveals an offshore ownership structure, that context gets passed forward into subsequent calls instead of relying solely on the original query entity. The supervisor controls sequencing; each specialist stays constrained by the tools it was given.
The agent layer in detail
InvestigationReport: typed Java record with findings, confidence levels, entity map, follow-up recommendationsEach agent is a Java interface wired via AiServices.builder() in AgentConfiguration, with one facade tool registered per agent. System prompt in /resources/prompts/<AgentName>-system.txt (editable without recompile). All agents share a single ChatModel bean pointing at the MLX server: model, temperature and max tokens come from the global mlx.* properties, not per-agent config. The facade tools and the two data tools they wrap are plain Spring @Component beans, so the only shared state between agents is those tool implementations.
Tools: the LLM’s hands
Every agent reaches live data through tools, which in LangChain4j means a Java method annotated with @Tool and exposed to the model as a callable function: the agent decides which tool to invoke, passes structured arguments, and gets back a result it can reason over. Without that layer the model works only from training weights and whatever you inject into the context window manually, and neither source contains current ownership structures, contract award histories, or jurisdiction-specific relationships.
@Component
public class GraphTraversalTool {
private final GraphService graph;
public GraphTraversalTool(GraphService graph) {
this.graph = graph;
}
@Tool("Find the Ultimate Beneficial Owner (UBO) of a company by traversing " +
"the ownership chain up to 5 hops. Returns the natural persons " +
"who ultimately control the company.")
public String findUBO(@P("Full legal name of the company") String companyName) {
var persons = graph.findUBO(companyName);
if (persons.isEmpty()) return "No UBO found for " + companyName;
return "ULTIMATE BENEFICIAL OWNERS of " + companyName + ":\n" +
persons.stream().map(this::formatPerson).collect(Collectors.joining("\n"));
}
@Tool("Detect potential conflicts of interest: find persons who held a " +
"public role at a body that issued contracts, and also owned or " +
"directed companies that won those contracts.")
public String detectConflictOfInterest(@P("Full name of the person") String personName,
@P("Start date ISO-8601, or null") String dateFrom,
@P("End date ISO-8601, or null") String dateTo) {
var conflicts = graph.detectConflictsForPerson(personName);
if (conflicts.isEmpty()) return "No conflicts of interest detected for " + personName;
return "CONFLICTS OF INTEREST DETECTED:\n" +
conflicts.stream().map(this::formatConflict).collect(Collectors.joining("\n"));
}
}
GraphService wraps the Neo4j repository. The specialist agents never see these methods directly. They call a facade tool (CorporateAgentTool, PersonProfileAgentTool, …) that composes several GraphTraversalTool and VectorSearchTool calls into a single string the model reasons over.
Tool methods return String rather than records or JSON, because the LLM reasons better over structured text than over nested objects. A return value like:
OWNERSHIP CHAIN for Costruzioni Ferretti Srl:
- Marco Ferretti → OWNS 77% (indirect, IT) via LuxHold SA
└─ LuxHold SA → CONTROLS 100% (LU) [TAX HAVEN]
- Mario Conti → OWNS 15% of LuxHold SA (IT) [FAMILY TIE: brother of Luigi Conti]
- Esposito Offshore Ltd → OWNS 8% (LU) [INACTIVE since 2021]
…lets the LLM reason over phrasing like [TAX HAVEN] or [INACTIVE] naturally, without extra instructions. The @Tool annotation text is the only contract between your framework and the model: a vague description sends the agent to the wrong tool, and a wrong one means the tool never gets called.
Data layer: graph and vector
Neo4j: structured relationships
The core question this system answers is whether a person who held public office had undisclosed financial ties to a company that won contracts during their tenure. That’s a traversal across multiple hops: person to public role, public role to contract, contract to company, company back to person through ownership or directorship. In a relational database that query needs recursive CTEs and multiple joins, and it gets harder to read and verify at every hop. In Neo4j it’s a single Cypher match that mirrors the domain model directly:
MATCH (p:Person)-[:HELD_PUBLIC_ROLE]->(pb:PublicBody)-[:ISSUED]->(ct:Contract)
-[:AWARDED_TO]->(co:Company)<-[:OWNS|IS_DIRECTOR_OF]-(p)
WHERE ct.awardedAt >= date($from) AND ct.awardedAt <= date($to)
RETURN p, pb, ct, co
The graph schema covers nine node types and around twenty relationship types:
The project uses Spring Data Neo4j (SDN 8). The repository is a single Neo4jRepository where every read is a @Query annotated with Cypher and bound to a projection record by RETURN-alias name, so the tool layer gets typed results instead of assembling strings. Writes are explicit MERGE statements rather than entity save(), because the seed path wants merge semantics and never round-trips full nodes. The earlier version used the raw Java Driver. Moving to SDN with hand-written @Query cut the boilerplate while keeping every query visible as Cypher, which is what you want when the domain is this query-heavy.
Qdrant: semantic meaning
Neo4j holds what already has a defined shape: persons, companies, contracts, public roles, shareholdings, each with a node type and explicit relationships between them. The rest of the investigative material, court records, news articles, ANAC filings, balance sheets, leaked files, does not normalise into a schema cleanly. The same fact appears in heterogeneous formats, paraphrased differently across sources, and what matters to an investigator is the meaning of the passage, not its structure. Qdrant is where those documents live, indexed as vectors so they can be searched by semantic similarity rather than by exact match.
Documents are chunked at 512 tokens with 64-token overlap and embedded with a Nomic ModernBERT model served locally via the MLX embed server. Each chunk stores metadata that bridges the vector and graph layers:
{
"source": "sole24ore-2022-05-12",
"source_type": "NEWS_ARTICLE",
"entity_ids": ["person:luigi-conti", "company:costruzioni-ferretti"],
"reliability": "HIGH",
"ingested_at": "2026-04-01T09:12:00Z"
}
entity_ids is what connects the two. DocumentAgent retrieves chunks from Qdrant and surfaces those IDs in its output, so a document hit can be lined up against the same persons and companies the graph specialists already returned, and the supervisor can treat semantic and structured evidence as part of the same case.
Observability
The hard part of running a multi-agent system is not the cluster of services, it is understanding what the system actually did to produce a given output. A single user query like “Who are the ultimate beneficial owners of Costruzioni Ferretti Srl?” expands into a dispatch tree that the supervisor builds at runtime: it decides which specialist to invoke, with what input string, in what order, and whether to call another one based on what came back. Two consecutive runs of the same query can take different paths. When a finding is wrong or low-confidence, the relevant question is which step in that tree produced it, and that is the question standard APM cannot answer.
What needs to be captured per query: the supervisor’s decomposition output, the ordered list of sub-agents it invoked, the input string passed to each (a paraphrase of the user query scoped to the specialist’s domain), the tools each sub-agent called with their arguments and return values, the token counts and latency per span, and the prompt version active at the time. Without all of these in one place, debugging an agentic pipeline is guesswork.
Langfuse captures this layer. Agent invocations become traces, tool calls become spans, and the LangChain4j integration writes everything automatically through LangfuseObservabilityListener. The screenshot below shows the supervisor’s dispatch for the Ferretti query: it called CorporateAgent first with "Investigate corporate ownership of: Costruzioni Ferretti Srl", then DocumentAgent with "Find documentary evidence about: Costruzioni Ferretti Srl ultimate beneficial owners ownership", then PersonProfileAgent on "Marco Ferretti" after CorporateAgent’s result surfaced him as the UBO. Each panel can be expanded to see the full input, the structured output, the tool calls underneath, and the token cost.
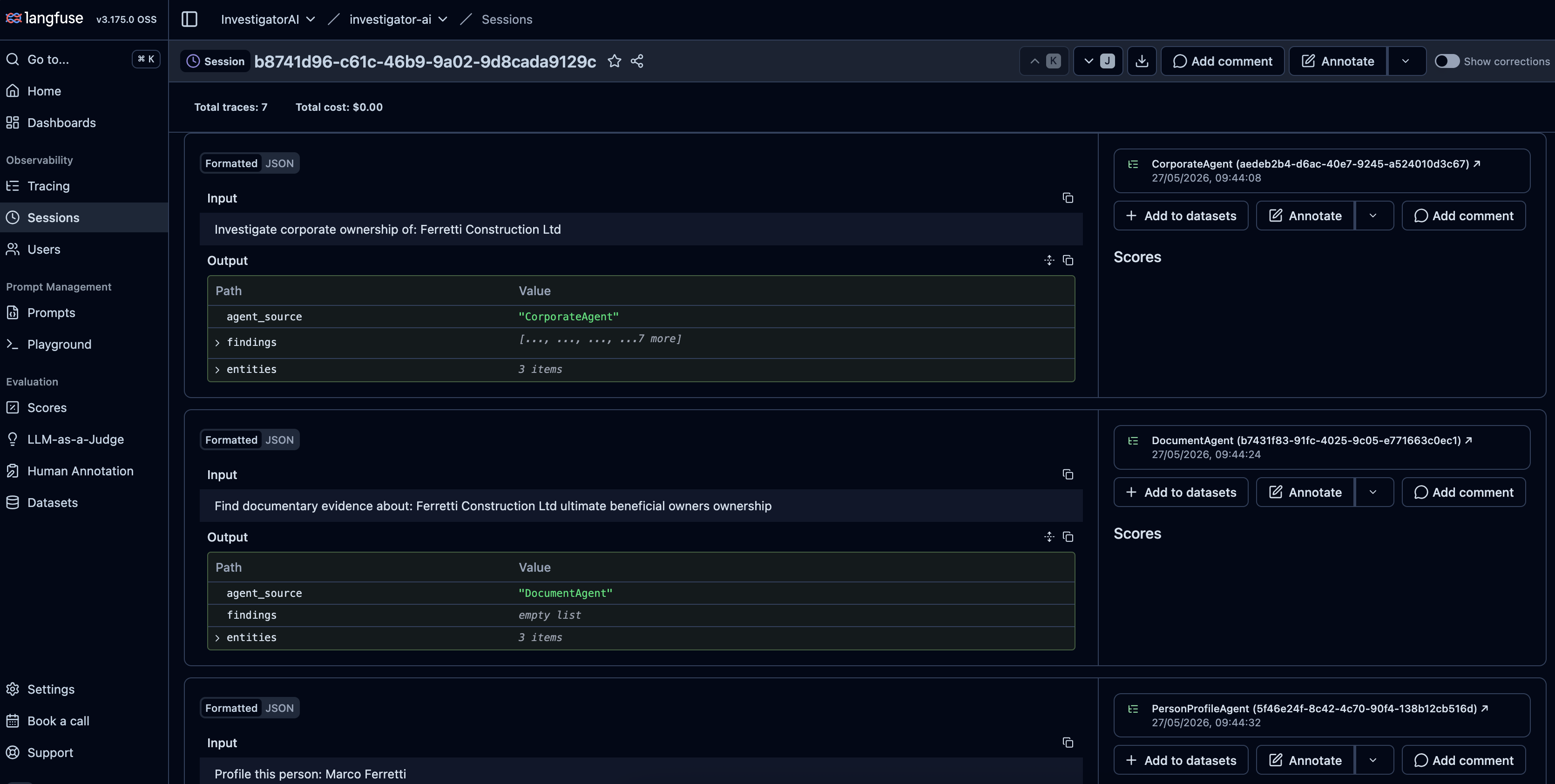
When the supervisor returns a low-confidence finding, you open the trace and walk backwards: which agent produced the claim, which tool call returned the underlying data, what the raw graph result actually contained. That walkback is only possible if the instrumentation captures LLM semantics, not just HTTP latency.
CorporateAgent-system.txt was active during which requests.
A complete request walkthrough
The same Ferretti query from the top of the article, traced end to end. The sequence is decided at runtime: the supervisor reads the query and focus entities, picks the first specialist to invoke, then chooses each subsequent step based on what came back. The order below is the one produced for this specific query.
POST /api/v1/investigate hits the Spring Boot API. InvestigationResource opens a Langfuse session, then builds the supervisor prompt from the query and the focus entities (Costruzioni Ferretti Srl, Marco Ferretti, Luigi Conti) passed in the request body, and calls supervisor.investigate(...). The raw query goes straight to the model.
findOwnershipChain, findUBO (Cypher up to 5 hops) and findContractsWonByCompany. Neo4j returns the path: Marco Ferretti → OWNS 77% → LuxHold SA → CONTROLS 100% → Costruzioni Ferretti Srl. The tool formats it as structured text. The agent produces a finding.
HELD_PUBLIC_ROLE) at the Comune di Brescia while his brother Mario (FAMILY_RELATION: SIBLING) owned 15% of LuxHold SA, which controls the company that won the contracts.
findContractsWonByCompany against Neo4j. The company won two public contracts from the Comune di Brescia inside the 2022-2023 window, the whole declared revenue for the period concentrated on a single awarding body.
entity_ids pointing to the same persons and companies already in the graph, so semantic and structured evidence line up.
InvestigationReport with executive summary, ordered findings, entity map, recommended follow-ups, and disclaimer. The response leaves the API as JSON.
localhost:3000: the supervisor span with the specialist spans nested under it, each facade tool call, token counts per model invocation, latency per span, prompt versions. If any finding is questionable, you can drill into the exact tool return that produced it.
Total latency on this query: 30-70 seconds with Qwen3.6-35B-A3B-4bit via Apple MLX on Apple Silicon, depending on how many specialist agents the supervisor invokes.
Running it
Full project at github.com/valeriomc/investigator-ai. The whole stack runs on a single Apple Silicon machine and assumes enough unified memory to keep both models resident alongside the Kubernetes cluster. The recommended baseline is 48 GB of unified memory; below that the host starts swapping while the models and the cluster compete for pages, and inference latency becomes unpredictable.
Two MLX servers must already be running on the host before any cluster command, exposed as OpenAI-compatible endpoints:
- chat model on
:8081servingmlx-community/Qwen3.6-35B-A3B-4bit - embedding model on
:8082servingmlx-community/nomicai-modernbert-embed-base-bf16
The two models combined hold around 22 GB of RAM while loaded, on top of the 6 GB and 4 CPU reserved by the Minikube profile for Neo4j, Qdrant, Postgres, Langfuse, and the two Spring services. Bootstrapping the MLX runtime and downloading the model weights is out of scope here, the project README covers it.
With the two endpoints reachable, bring up the cluster:
make up
make seed
make investigate
make up verifies that both MLX endpoints respond before doing anything else; if either is missing the target fails immediately, with no half-deployed Kubernetes state to clean up. After that it creates the Minikube profile, builds the container images inside Minikube, deploys infrastructure and services, and starts the port-forwards. make seed loads the Ferretti scenario (14 nodes, 19 relationships) into Neo4j and embeds the matching documents into Qdrant. make investigate fires the reference query against the seeded data and prints the InvestigationReport to stdout. The full Langfuse trace is at localhost:3000.
What’s not in here yet
The architecture is already the part that works. What is still missing sits on either side of it.
Right now, document ingestion is still a manual step. The current make seed command loads fixture data into both Qdrant and Neo4j, but there is no production pipeline that continuously ingests new filings, extracts entities, and keeps both stores aligned in a consistent way. Until that exists, every new investigation depends on hand-curated data prepared in advance.
There is no entity resolution layer. At the moment, tools rely on exact string matching inside Cypher queries. That makes the system brittle in practice: a slightly different spelling, a missing accent, or a company name that has evolved over time can all lead to empty results, even when the underlying entity exists. A proper solution needs fuzzy matching, combining approaches like trigram similarity and Jaro-Winkler distance to handle name variants and partial matches, while still being precise enough to avoid false positives. Any uncertain match also needs to be surfaced back to the supervisor rather than silently dropped.
There is no automated evaluation of findings. Confidence levels are assigned by SourceVerificationAgent based on cross-referenced evidence, but no held-out test set says “given this query, the supervisor should produce these findings at these confidence levels”. Prompt changes are evaluated by reading traces, which works at this scale and stops working past a handful of investigation types.
The decomposition logic, tool grounding, and observability are solid. The production gap is not in the agents themselves, but in the ingestion pipeline before them and the validation layer around the agents.